やりたいことはこちら。簡単に言うと、FF14というゲームのスクリーンショットをTensorFlow・Object Detection APIを使って加工するLambda関数を作りたいということです。
前回の記事はこちらです
前回は、AWS ECRを使ってAWS Lambda関数のイメージを作ってアップロードしてテストするところまでをやりました。今回はAWS S3に画像を置いて、その画像をAWS Lambdaで加工するテストをしたいです。
参考にした記事
AWS Lambdaで画像ファイル加工~環境構築から実行確認まで~ 手順紹介
画像加工のスクリプトや、S3を使う方法などの参考にしました。
business.ntt-east.co.jp
Docker コンテナの中に入ってBashなどでコマンド実行をする
デバッグ作業で使いました。
zukucode.com
AWS Lambda関数を実行してS3にファイルを保存、追記してみる
テキストファイルを実際にS3に入れてみました。
sugimonblog.com
AWSのLambdaとS3連携でハマる所
IAM権限などでハマったので私も参考にしました。
lets-hack.tech
やったこと
画像加工を行うスクリプトのDockerイメージを作る
AWS ECR + Lambdaで作業を行いたいので(おそらくその方が管理が楽なので)、Dockerイメージを作成。前回はecr-tutorialでしたが、今回は自作のイメージを。ほぼ前回のecr-tutorialのマネですが。
実際にapp.pyを書いてみた
import json import os import sys import uuid from urllib.parse import unquote_plus from PIL import Image import PIL.Image def handler(event, context): resize_image('/tmp/input.png', '/tmp/output.png') return { "statusCode": 200, "body": json.dumps({"tokens": "ok"}) } def resize_image(image_path, resized_path): //Pillowの機能を使用した画像データ処理用関数 with Image.open(image_path) as image: //画像ファイルから画像データを取得 image.thumbnail(tuple(x / 2 for x in image.size) //画像データサイズを1/2に縮小 image.save(resized_path) //Lambda内の一時保存先に保存
これを実行
> docker-compose up -d --build > curl -d '{\"sentence\":\"I am Taro Yamada.\"}' -H "Content-Type: application/json" http://localhost:9000/2015-03-31/functions/function/invocations {"errorMessage": "Syntax error in module 'app': invalid syntax (app.py, line 21)", "errorType": "Runtime.UserCodeSyntaxError", "stackTrace": [" File \"/var/task/app.py\" Line 21\n def resize_image(image_path, resized_path):\t//Pillow\u306e\u6a5f\u80fd\u3092\u4f7f\u7528\u3057\u305f\u753b\u50cf\u30c7\u30fc\u30bf\u51e6\u7406\u7528\u95a2\u6570\n"]}
なぞのエラーメッセージが返ってくる
Dockerの中身を覗きに行ってくる
bashの起動
上記サイトを参考にDocker内のbashを起動
> docker exec -it c77ce06fc615 /bin/bash bash-4.2# ls app.py bash-4.2# pwd /var/task bash-4.2# python app.py File "app.py", line 21 def resize_image(image_path, resized_path): //Pillowの機能を使用した画像データ処理用関数 ^ SyntaxError: invalid syntax
ああ、なるほどね。日本語ね。Dockerの中に入るとエラーメッセージやデバッグがやりやすくていいですね。
色々修正
app.pyを修正
import json import os import sys import uuid from urllib.parse import unquote_plus from PIL import Image import PIL.Image def handler(event, context): resize_image('/tmp/input.png', '/tmp/output.png') return { "statusCode": 200, "body": json.dumps({"tokens": "ok"}) } def resize_image(image_path, resized_path): with Image.open(image_path) as image: image.thumbnail(tuple(x / 2 for x in image.size)) image.save(resized_path)
実行
> curl -d '{\"sentence\":\"I am Taro Yamada.\"}' -H "Content-Type: application/json" http://localhost:9000/2015-03-31/functions/function/invocations {"statusCode": 200, "body": "{\"tokens\": \"ok\"}"}
bashで入って、/tmp/output.pngが作られているか確認
> docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 4dafbd65075f languageecho-lambda "/lambda-entrypoint.…" 4 minutes ago Up 4 minutes 127.0.0.1:9000->8080/tcp languageecho-lambda_languageecho-lambda_1 > docker exec -it 4dafbd65075f /bin/bash bash-4.2# ls /tmp init.py input.png output.png
無事確認。
実際にファイルをS3に書き込んでみる
コードを少し修正
import boto3 import json import os import sys import uuid from urllib.parse import unquote_plus from PIL import Image import PIL.Image from datetime import datetime s3 = boto3.resource('s3') bucket = s3.Bucket('languageecho') def handler(event, context): bucket = 'languageecho' key = 'output/test_' + datetime.now().strftime('%Y-%m-%d-%H-%M-%S') + '.txt' file_contents = json.dumps(event) obj = s3.Object(bucket,key) obj.put( Body=file_contents ) #resize_image('/tmp/input.png', '/tmp/output.png') return { "statusCode": 200, "body": json.dumps({"tokens": "ok"}) }
合わせて Dockerfileも修正
以下を追記
RUN pip3 install boto3
S3にバケットを作成し、実行IAMロールで許可を与える
バケット名は「languageecho」。予め作っておいたIAMロールが「arn:aws:iam::****:role/languageechoIAM」になります。このポリシーだとS3に対して全許可になるので、本当はもう少し直したほうが良いかなとは思っています。
{
"Version": "2012-10-17",
"Id": "Policy1653113200209",
"Statement": [
{
"Sid": "Stmt1653113194115",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::****:role/languageechoIAM"
},
"Action": "s3:*",
"Resource": "arn:aws:s3:::languageecho/*"
}
]
}
実際にテストする
Lambdaからテストすると、S3にファイルが作成されていました。
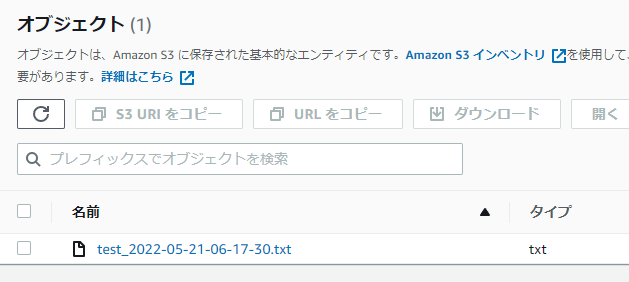
実際に画像処理して画像ファイルをS3を書き込む
プログラムを直し
関数を修正
import boto3 import json import os import sys import uuid from urllib.parse import unquote_plus from PIL import Image import PIL.Image from datetime import datetime s3 = boto3.resource('s3') def handler(event, context): bucket = s3.Bucket('languageecho') bucket.download_file('input/input.png', '/tmp/input.png') resize_image('/tmp/input.png', '/tmp/output.png') bucket.upload_file('/tmp/output.png', 'output/output.png') return { "statusCode": 200, "body": json.dumps({"tokens": "ok"}) } def resize_image(image_path, resized_path): with Image.open(image_path) as image: image.thumbnail(tuple(x / 2 for x in image.size)) image.save(resized_path)
実際に実行してみる
画像サイズが小さめのファイルが、ちゃんと書き出されていました。
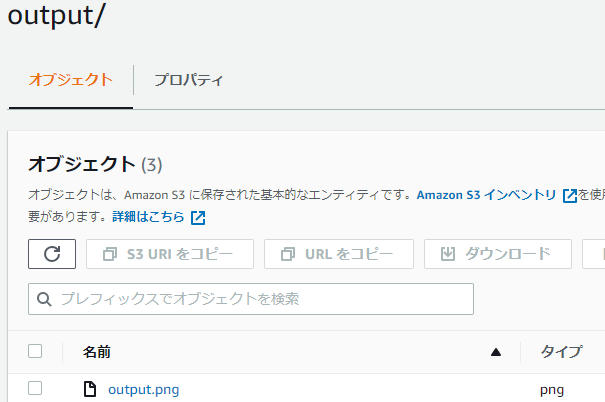
終わりに、ECRの中身を整理
多分、イメージさえ消しておけば課金されないので、ECRのイメージを消して作業終了。
今後の予定
前回の記事の予定の部分から画像処理の部分を抜いた話になるのですが、一応転載を。
JavaScriptでAmazon S3にファイルをアップロード
このあたりが参考になりそうです
qiita.com
S3に画像ファイルを置けば、Lambdaから読み込んで加工できるという寸法です。
S3に処理された画像が書き込まれたら、画像を表示するWeb UIを作る
S3の特定のURLにファイルが書き込まれるはずです、Web UI側でファイルの存在をJavaScriptで(1秒ごとにチェックしにいくとかで)検知し、表示させます。
LambdaでTensorFlowを動かす
ファイル加工部分をTensorFlowにし、TensorFlowさえ動けば「言語を超える力」の処理が行なえます。書き込みはS3にそのまま書き込みます。
あと追記で
S3に溜まっていく一時ファイルを消すようにしたい
1日に1回ぐらいは整理するようにしたいです。ライフサイクルというのでできるようです
www.kabegiwablog.com







